Exemplos e aplicações
Nesta lição, vamos explorar alguns exemplos de algoritmos variacionais e como aplicá-los:
- Como escrever um algoritmo variacional personalizado
- Como aplicar um algoritmo variacional para encontrar autovalores mínimos
- Como utilizar algoritmos variacionais para resolver casos de uso em aplicações reais
Observe que o framework de padrões do Qiskit pode ser aplicado a todos os problemas que apresentamos aqui. No entanto, para evitar repetição, vamos destacar explicitamente as etapas do framework em apenas um exemplo, executado em hardware real.
Definições dos problemas
Imagine que queremos usar um algoritmo variacional para encontrar o autovalor do seguinte observável:
Esse observável tem os seguintes autovalores:
E autoestados:
# Added by doQumentation — required packages for this notebook
!pip install -q numpy qiskit qiskit-ibm-runtime rustworkx scipy
from qiskit.quantum_info import SparsePauliOp
observable_1 = SparsePauliOp.from_list([("II", 2), ("XX", -2), ("YY", 3), ("ZZ", -3)])
VQE personalizado
Vamos começar explorando como construir uma instância de VQE manualmente para encontrar o autovalor mais baixo de . Isso vai incorporar diversas técnicas que abordamos ao longo deste curso.
def cost_func_vqe(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
return cost
from qiskit.circuit.library.n_local import n_local
from qiskit import QuantumCircuit
import numpy as np
reference_circuit = QuantumCircuit(2)
reference_circuit.x(0)
variational_form = n_local(
num_qubits=2,
rotation_blocks=["rz", "ry"],
entanglement_blocks="cx",
entanglement="linear",
reps=1,
)
raw_ansatz = reference_circuit.compose(variational_form)
raw_ansatz.decompose().draw("mpl")
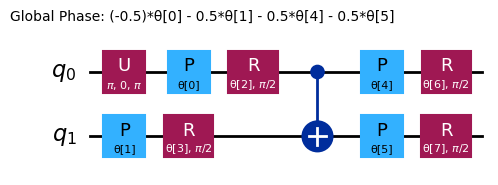
Vamos começar a depuração com simuladores locais.
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
estimator = Estimator()
sampler = Sampler()
Agora definimos um conjunto inicial de parâmetros:
x0 = np.ones(raw_ansatz.num_parameters)
print(x0)
[1. 1. 1. 1. 1. 1. 1. 1.]
Podemos minimizar essa função de custo para calcular os parâmetros ótimos:
# SciPy minimizer routine
from scipy.optimize import minimize
import time
start_time = time.time()
result = minimize(
cost_func_vqe,
x0,
args=(raw_ansatz, observable_1, estimator),
method="COBYLA",
options={"maxiter": 1000, "disp": True},
)
end_time = time.time()
execution_time = end_time - start_time
Return from COBYLA because the trust region radius reaches its lower bound.
Number of function values = 103 Least value of F = -5.999999998357189
The corresponding X is:
[2.27483579e+00 8.37593091e-01 1.57080508e+00 5.82932911e-06
2.49973063e+00 6.41884255e-01 6.33686904e-01 6.33688223e-01]
result
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -5.999999998357189
x: [ 2.275e+00 8.376e-01 1.571e+00 5.829e-06 2.500e+00
6.419e-01 6.337e-01 6.337e-01]
nfev: 103
maxcv: 0.0
Como esse problema de exemplo usa apenas dois qubits, podemos verificar o resultado utilizando o solucionador de álgebra linear do NumPy.
from numpy.linalg import eigvalsh
solution_eigenvalue = min(eigvalsh(observable_1.to_matrix()))
print(f"""Number of iterations: {result.nfev}""")
print(f"""Time (s): {execution_time}""")
print(
f"Percent error: {100*abs((result.fun - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
Number of iterations: 103
Time (s): 0.4394676685333252
Percent error: 2.74e-08
Como você pode ver, o resultado é extremamente próximo do ideal.
Experimentando para melhorar velocidade e precisão
Adicionar estado de referência
No exemplo anterior, não usamos nenhum operador de referência . Agora vamos pensar em como o autoestado ideal pode ser obtido. Considere o seguinte circuito.
from qiskit import QuantumCircuit
ideal_qc = QuantumCircuit(2)
ideal_qc.h(0)
ideal_qc.cx(0, 1)
ideal_qc.draw("mpl")

Podemos verificar rapidamente que esse circuito nos dá o estado desejado.
from qiskit.quantum_info import Statevector
Statevector(ideal_qc)
Statevector([0.70710678+0.j, 0. +0.j, 0. +0.j,
0.70710678+0.j],
dims=(2, 2))
Agora que vimos como é um circuito que prepara o estado solução, parece razoável usar uma porta Hadamard como circuito de referência, de modo que o ansatz completo se torna:
reference = QuantumCircuit(2)
reference.h(0)
reference.cx(0, 1)
# Include barrier to separate reference from variational form
reference.barrier()
ref_ansatz = variational_form.decompose().compose(reference, front=True)
ref_ansatz.draw("mpl")
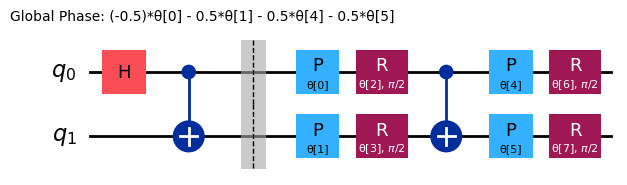
Para esse novo circuito, a solução ideal poderia ser alcançada com todos os parâmetros definidos como , o que confirma que a escolha do circuito de referência é razoável.
Agora vamos comparar o número de avaliações da função de custo, as iterações do otimizador e o tempo gasto em relação à tentativa anterior.
import time
start_time = time.time()
ref_result = minimize(
cost_func_vqe, x0, args=(ref_ansatz, observable_1, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
Usando nossos parâmetros ótimos para calcular o autovalor mínimo:
experimental_min_eigenvalue_ref = cost_func_vqe(
ref_result.x, ref_ansatz, observable_1, estimator
)
print(experimental_min_eigenvalue_ref)
-5.999999996759607
print("ADDED REFERENCE STATE:")
print(f"""Number of iterations: {ref_result.nfev}""")
print(f"""Time (s): {execution_time}""")
print(
f"Percent error: {100*abs((experimental_min_eigenvalue_ref - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
ADDED REFERENCE STATE:
Number of iterations: 127
Time (s): 0.5620882511138916
Percent error: 5.40e-08
Dependendo do seu sistema específico, isso pode ou não resultar em melhora de velocidade ou precisão nesse exemplo de escala muito pequena. O ponto importante é que começar com estados de referência fisicamente motivados se torna cada vez mais relevante para melhorar velocidade e precisão à medida que os problemas crescem em escala.
Alterar o ponto inicial
Agora que vimos o efeito de adicionar o estado de referência, vamos explorar o que acontece quando escolhemos diferentes pontos iniciais . Em particular, vamos usar e .
Lembre que, como discutido quando o estado de referência foi introduzido, a solução ideal seria encontrada quando todos os parâmetros são , portanto o primeiro ponto inicial deve exigir menos avaliações.
import time
start_time = time.time()
x0 = [0, 0, 0, 0, 6, 0, 0, 0]
x0_1_result = minimize(
cost_func_vqe, x0, args=(raw_ansatz, observable_1, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
print("INITIAL POINT 1:")
print(f"""Number of iterations: {x0_1_result.nfev}""")
print(f"""Time (s): {execution_time}""")
INITIAL POINT 1:
Number of iterations: 108
Time (s): 0.4492197036743164
Ajustando o ponto inicial para :
import time
start_time = time.time()
x0 = 6 * np.ones(raw_ansatz.num_parameters)
x0_2_result = minimize(
cost_func_vqe, x0, args=(raw_ansatz, observable_1, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
print("INITIAL POINT 2:")
print(f"""Number of iterations: {x0_2_result.nfev}""")
print(f"""Time (s): {execution_time}""")
INITIAL POINT 2:
Number of iterations: 107
Time (s): 0.40889453887939453
Ao experimentar diferentes pontos iniciais, você pode conseguir convergência mais rápida e com menos avaliações de função.
Experimentando diferentes otimizadores
Podemos ajustar o otimizador usando o argumento method do minimize do SciPy, com mais opções disponíveis aqui. Originalmente usamos um minimizador com restrições (COBYLA). Neste exemplo, vamos explorar o uso de um minimizador sem restrições (BFGS).
import time
start_time = time.time()
result = minimize(
cost_func_vqe, x0, args=(raw_ansatz, observable_1, estimator), method="BFGS"
)
end_time = time.time()
execution_time = end_time - start_time
print("CHANGED TO BFGS OPTIMIZER:")
print(f"""Number of iterations: {result.nfev}""")
print(f"""Time (s): {execution_time}""")
CHANGED TO BFGS OPTIMIZER:
Number of iterations: 117
Time (s): 0.31656408309936523
Exemplo de VQD
Aqui implementamos explicitamente o framework de padrões do Qiskit.
Passo 1: Mapear entradas clássicas para um problema quântico
Agora, em vez de buscar apenas o menor autovalor dos nossos observáveis, vamos buscar todos os (onde ).
Lembre-se de que as funções de custo do VQD são:
Isso é especialmente importante porque um vetor (neste caso ) deve ser passado como argumento ao definir o objeto VQD.
Além disso, na implementação do VQD pelo Qiskit, em vez de considerar os observáveis efetivos descritos no notebook anterior, as fidelidades são calculadas diretamente via o algoritmo ComputeUncompute, que utiliza uma primitiva Sampler para amostrar a probabilidade de obter para o circuito
. Isso funciona exatamente porque essa probabilidade é
ansatz = n_local(
num_qubits=2,
rotation_blocks=["ry", "rz"],
entanglement_blocks="cz",
# entanglement="linear",
reps=1,
)
ansatz.decompose().draw("mpl")
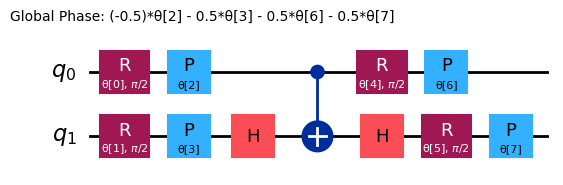
Vamos começar examinando o seguinte observável:
Esse observável possui os seguintes autovalores:
E autoestados:
from qiskit.quantum_info import SparsePauliOp
observable_2 = SparsePauliOp.from_list([("II", 2), ("XX", -3), ("YY", 2), ("ZZ", -4)])
A seguir, adicionamos a função de custo do VQD. Note que, em comparação com a lição anterior, agora temos dois argumentos adicionais (realbackend e backend) para auxiliar na transpilação quando usamos backends reais.
import numpy as np
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
def calculate_overlaps(
ansatz, prev_circuits, parameters, sampler, realbackend, backend
):
def create_fidelity_circuit(circuit_1, circuit_2):
if len(circuit_1.clbits) > 0:
circuit_1.remove_final_measurements()
if len(circuit_2.clbits) > 0:
circuit_2.remove_final_measurements()
circuit = circuit_1.compose(circuit_2.inverse())
circuit.measure_all()
return circuit
overlaps = []
for prev_circuit in prev_circuits:
fidelity_circuit = create_fidelity_circuit(ansatz, prev_circuit)
if realbackend == 1:
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
fidelity_circuit = pm.run(fidelity_circuit)
sampler_job = sampler.run([(fidelity_circuit, parameters)])
meas_data = sampler_job.result()[0].data.meas
counts_0 = meas_data.get_int_counts().get(0, 0)
shots = meas_data.num_shots
overlap = counts_0 / shots
overlaps.append(overlap)
return np.array(overlaps)
Usaremos a seguinte função para calcular a penalidade de sobreposição. Note que isso ainda faz parte do mapeamento do problema para circuitos quânticos. Porém, como discutido na lição anterior, essa função calcula a sobreposição entre um circuito variacional atual e o circuito otimizado de um estado anterior de menor energia/custo obtido. O novo circuito gerado também precisa ser transpilado para rodar em hardware real. Já vimos essa função usada em um simulador. Aqui, já precisamos considerar a transpilação e a otimização relacionada para quando usarmos um backend real — daí as linhas ao redor de if realbackend == 1. Isso mistura um pouco o passo 2, mas vamos explicitar o passo 2 mais adiante.
def cost_func_vqd(
parameters,
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
hamiltonian,
realbackend,
backend,
):
estimator_job = estimator.run([(ansatz, hamiltonian, [parameters])])
total_cost = 0
if step > 1:
overlaps = calculate_overlaps(
ansatz, prev_states, parameters, sampler, realbackend, backend
)
total_cost = np.sum(
[np.real(betas[state] * overlap) for state, overlap in enumerate(overlaps)]
)
estimator_result = estimator_job.result()[0]
value = estimator_result.data.evs[0] + total_cost
return value
Mais uma vez, usaremos simuladores para depuração e, em seguida, passaremos para hardware real.
from qiskit.primitives import StatevectorSampler
from qiskit.primitives import StatevectorEstimator
sampler = StatevectorSampler(default_shots=4092)
estimator = StatevectorEstimator()
Aqui introduzimos o número de estados que desejamos calcular, as penalidades e um conjunto de parâmetros iniciais, x0.
from qiskit.quantum_info import SparsePauliOp
k = 4
betas = [50, 60, 40]
x0 = np.ones(8)
Vamos agora testar o algoritmo usando simuladores:
from scipy.optimize import minimize
prev_states = []
prev_opt_parameters = []
eigenvalues = []
realbackend = 0
for step in range(1, k + 1):
if step > 1:
prev_states.append(ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
observable_2,
realbackend,
None,
),
method="COBYLA",
options={"maxiter": 200, "tol": 0.000001},
)
print(result)
prev_opt_parameters = result.x
eigenvalues.append(result.fun)
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -6.9999999999996
x: [ 1.571e+00 1.571e+00 2.519e+00 2.100e+00 1.242e+00
6.935e-01 2.298e+00 1.991e+00]
nfev: 151
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 3.698974255258432
x: [ 1.269e+00 1.109e+00 1.080e+00 1.200e+00 1.094e+00
1.163e+00 9.752e-01 9.519e-01]
nfev: 103
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 4.731320121938101
x: [ 1.533e+00 2.451e+00 2.526e+00 2.406e+00 1.968e+00
2.105e+00 8.537e-01 8.442e-01]
nfev: 110
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 7.008239313655201
x: [ 4.150e+00 2.120e+00 3.495e+00 7.262e-01 1.953e+00
-1.982e-01 3.263e-01 2.563e+00]
nfev: 126
maxcv: 0.0
eigenvalues
[np.float64(-6.9999999999996),
np.float64(3.698974255258432),
np.float64(4.731320121938101),
np.float64(7.008239313655201)]
Esses resultados são bastante próximos dos esperados, exceto pelo erro de aproximação e pela fase global. Poderíamos ajustar a tolerância do otimizador clássico e/ou as penalidades para sobreposição de vetores de estado a fim de obter valores mais precisos.
solution_eigenvalues = [-7, 3, 5, 7]
for index, experimental_eigenvalue in enumerate(eigenvalues):
solution_eigenvalue = solution_eigenvalues[index]
print(
f"Percent error: {abs((experimental_eigenvalue - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
Percent error: 5.71e-14
Percent error: 2.33e-01
Percent error: 5.37e-02
Percent error: 1.18e-03
Alterar betas
Como mencionado na lição anterior, os valores de devem ser maiores do que a diferença entre os autovalores. Vamos ver o que acontece quando eles não satisfazem essa condição com
com autovalores
from qiskit.quantum_info import SparsePauliOp
k = 4
betas = np.ones(3)
x0 = np.zeros(8)
from scipy.optimize import minimize
prev_states = []
prev_opt_parameters = []
eigenvalues = []
realbackend = 0
for step in range(1, k + 1):
if step > 1:
prev_states.append(ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
observable_2,
realbackend,
None,
),
method="COBYLA",
options={"tol": 0.01, "maxiter": 200},
)
print(result)
prev_opt_parameters = result.x
eigenvalues.append(result.fun)
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -6.999916534745094
x: [ 1.568e+00 -1.569e+00 1.385e-01 1.398e-01 -7.972e-01
7.835e-01 -2.375e-01 4.539e-02]
nfev: 125
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -1.515139929812874
x: [-5.317e-04 -2.514e-03 1.016e+00 9.998e-01 3.890e-04
1.772e-04 1.568e-04 8.497e-04]
nfev: 35
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -0.509948114293115
x: [-3.796e-03 8.853e-03 3.015e-04 9.997e-01 6.271e-04
-2.554e-03 1.017e-04 2.766e-04]
nfev: 37
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 0.4914672235935682
x: [-7.178e-03 -8.652e-03 1.125e+00 -5.428e-02 -1.586e-03
2.031e-03 -3.462e-03 5.734e-03]
nfev: 35
maxcv: 0.0
solution_eigenvalues = [-7, 3, 5, 7]
for index, experimental_eigenvalue in enumerate(eigenvalues):
solution_eigenvalue = solution_eigenvalues[index]
print(
f"Percent error: {abs((experimental_eigenvalue - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
Percent error: 1.19e-05
Percent error: 1.51e+00
Percent error: 1.10e+00
Percent error: 9.30e-01
Desta vez, o otimizador retorna o mesmo estado como solução proposta para todos os autoestados — o que está claramente errado. Isso acontece porque os betas eram pequenos demais para penalizar o autoestado mínimo nas funções de custo sucessivas. Portanto, ele não foi excluído do espaço de busca efetivo nas iterações seguintes do algoritmo, sendo sempre escolhido como a melhor solução possível.
Recomendamos experimentar com os valores de , garantindo que sejam maiores do que a diferença entre os autovalores.
Passo 2: Otimizar o problema para execução quântica
Para rodar no hardware real, precisamos otimizar os circuitos quânticos para o computador quântico escolhido. Para nossos propósitos aqui, usaremos simplesmente o backend menos ocupado.
from qiskit_ibm_runtime import SamplerV2 as Sampler
from qiskit_ibm_runtime import EstimatorV2 as Estimator
from qiskit_ibm_runtime import Session, EstimatorOptions
from qiskit_ibm_runtime import QiskitRuntimeService
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
# Or use a specific backend
# backend = service.backend("ibm_brisbane")
print(backend)
<IBMBackend('ibm_brisbane')>
Vamos transpilar nosso circuito usando um gerenciador de passagens predefinido com nível de otimização 3.
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
isa_ansatz = pm.run(ansatz)
isa_observable = observable_2.apply_layout(layout=isa_ansatz.layout)
Passo 3: Executar usando as primitivas do Qiskit
Ajustando os betas para valores suficientemente altos, podemos agora rodar nosso cálculo em hardware quântico real.
# Estimated compute resource usage: 25 minutes.
# Benchmarked at 24 min, 30 sec on an Eagle r3 processor on 5-30-24
k = 2
betas = [30, 50, 80]
x0 = np.zeros(8)
real_prev_states = []
real_prev_opt_parameters = []
real_eigenvalues = []
realbackend = 1
estimator_options = EstimatorOptions(resilience_level=1, default_shots=10_000)
with Session(backend=backend) as session:
estimator = Estimator(mode=session, options=estimator_options)
sampler = Sampler(mode=session)
for step in range(1, k + 1):
if step > 1:
real_prev_states.append(isa_ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
isa_ansatz,
real_prev_states,
step,
betas,
estimator,
sampler,
isa_observable,
realbackend,
backend,
),
method="COBYLA",
options={"maxiter": 200},
)
print(result)
real_prev_opt_parameters = result.x
real_eigenvalues.append(result.fun)
session.close()
print(real_eigenvalues)
Passo 4: Pós-processar e retornar o resultado em formato clássico
Nossa saída é estruturalmente similar ao que foi discutido nas lições e exemplos anteriores. Mas há algo problemático nos resultados acima, do qual podemos extrair uma lição importante no contexto de estados excitados. Para limitar o tempo de computação neste exemplo didático, definimos um número máximo de iterações para o otimizador clássico que pode ter sido baixo demais: 200 iterações. Um cálculo anterior feito acima, em simulador, não convergiu em 200 iterações. Aqui, o nosso convergiu... mas com qual tolerância? Não especificamos uma tolerância para que o COBYLA considerasse a si mesmo "convergido". Uma rápida olhada no valor da função e a comparação com execuções anteriores nos diz que o COBYLA não estava perto de convergir com a precisão que exigimos.
Há outro problema: a energia do primeiro estado excitado parece ser menor do que a energia do estado fundamental! Veja se você consegue explicar como isso pode acontecer. Dica: está relacionado ao ponto de convergência que acabamos de abordar. Esse comportamento é explicado em detalhes mais adiante, após a aplicação do VQD à molécula H2.
Química quântica: solver de estado fundamental e estados excitados
Nosso objetivo é minimizar o valor esperado do observável que representa a energia (Hamiltoniano ):
from qiskit.quantum_info import SparsePauliOp
from qiskit.circuit.library import efficient_su2
H2_op = SparsePauliOp.from_list(
[
("II", -1.052373245772859),
("IZ", 0.39793742484318045),
("ZI", -0.39793742484318045),
("ZZ", -0.01128010425623538),
("XX", 0.18093119978423156),
]
)
chem_ansatz = efficient_su2(H2_op.num_qubits)
chem_ansatz.decompose().draw("mpl")
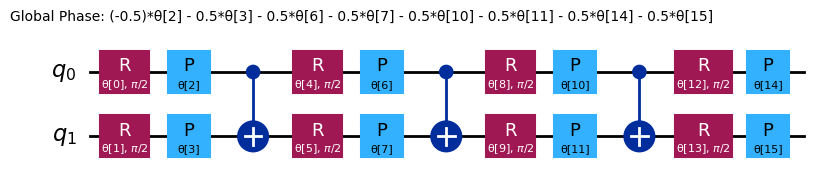
from qiskit import QuantumCircuit
def cost_func_vqe(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
# cost = estimator.run(ansatz, hamiltonian, parameter_values=params).result().values[0]
return cost
Agora definimos um conjunto inicial de parâmetros:
import numpy as np
x0 = np.ones(chem_ansatz.num_parameters)
Podemos minimizar essa função de custo para calcular os parâmetros ótimos, e podemos verificar nosso código primeiro usando um simulador local.
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
estimator = Estimator()
sampler = Sampler()
# SciPy minimizer routine
from scipy.optimize import minimize
import time
start_time = time.time()
result = minimize(
cost_func_vqe, x0, args=(chem_ansatz, H2_op, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
result
message: Optimization terminated successfully.
success: True
status: 1
fun: -1.857275029048451
x: [ 7.326e-01 1.354e+00 ... 1.040e+00 1.508e+00]
nfev: 242
maxcv: 0.0
O valor mínimo da função de custo (-1.857...) é a energia do estado fundamental da molécula H2, em unidades de hartrees.
Estados excitados
Também podemos usar o VQD para resolver estados totais (o estado fundamental e o primeiro estado excitado).
from qiskit.quantum_info import SparsePauliOp
import numpy as np
k = 2
betas = [33, 33]
# x0 = np.zeros(ansatz.num_parameters)
x0 = [
1.164e00,
-2.438e-01,
9.358e-04,
6.745e-02,
1.990e00,
9.810e-02,
6.154e-01,
5.454e-01,
]
Vamos adicionar o cálculo de sobreposição:
from scipy.optimize import minimize
prev_states = []
prev_opt_parameters = []
eigenvalues = []
realbackend = 0
for step in range(1, k + 1):
if step > 1:
prev_states.append(ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
H2_op,
realbackend,
None,
),
method="COBYLA",
options={"tol": 0.001, "maxiter": 2000},
)
print(result)
prev_opt_parameters = result.x
eigenvalues.append(result.fun)
message: Optimization terminated successfully.
success: True
status: 1
fun: -1.8572671093941977
x: [ 1.164e+00 -2.437e-01 2.118e-03 6.448e-02 1.990e+00
9.870e-02 6.167e-01 5.476e-01]
nfev: 58
maxcv: 0.0
message: Optimization terminated successfully.
success: True
status: 1
fun: -1.0322873777662176
x: [ 3.205e+00 1.502e+00 1.699e+00 -1.107e-02 3.086e+00
1.530e+00 4.445e-02 7.013e-02]
nfev: 99
maxcv: 0.0
eigenvalues
[-1.8572671093941977, -1.0322873777662176]
Hardware real e um aviso final importante
Para executar isso em hardware real, precisamos otimizar os circuitos quânticos para o computador quântico escolhido. Para nossos fins, vamos simplesmente usar o backend menos ocupado.
from qiskit_ibm_runtime import SamplerV2 as Sampler
from qiskit_ibm_runtime import EstimatorV2 as Estimator
from qiskit_ibm_runtime import Session, EstimatorOptions
from qiskit_ibm_runtime import QiskitRuntimeService
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
Vamos usar um pass manager predefinido para a transpilação, e otimizaremos ao máximo nosso circuito usando o nível de otimização 3.
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
isa_ansatz = pm.run(ansatz)
isa_observable = H2_op.apply_layout(layout=isa_ansatz.layout)
Como o VQD é altamente iterativo, vamos executar todas as etapas dentro de uma sessão do Runtime, de modo que nossos jobs só sejam enfileirados no início, e não a cada atualização de parâmetros. Nada mais muda na sintaxe da função de custo ou do estimador.
x0 = [
1.306e00,
-2.284e-01,
6.913e-02,
-2.530e-02,
1.849e00,
7.433e-02,
6.366e-01,
5.600e-01,
]
# Estimated hardware usage: 20 min benchmarked on an Eagle r3 processor on 5-30-24
real_prev_states = []
real_prev_opt_parameters = []
real_eigenvalues = []
realbackend = 1
estimator_options = EstimatorOptions(resilience_level=1, default_shots=4096)
with Session(backend=backend) as session:
estimator = Estimator(mode=session)
sampler = Sampler(mode=session)
for step in range(1, k + 1):
if step > 1:
real_prev_states.append(
isa_ansatz.assign_parameters(real_prev_opt_parameters)
)
result = minimize(
cost_func_vqd,
x0,
args=(
isa_ansatz,
real_prev_states,
step,
betas,
estimator,
sampler,
isa_observable,
realbackend,
backend,
),
method="COBYLA",
options={"tol": 0.001, "maxiter": 300},
)
print(result)
real_prev_opt_parameters = result.x
real_eigenvalues.append(result.fun)
session.close()
print(real_eigenvalues)
A energia do estado fundamental obtida (-1,83 hartrees) não está muito longe do valor correto (-1,85 hartrees). No entanto, a energia do estado excitado ficou bem distante. Esse comportamento é semelhante ao erro que observamos anteriormente nesta lição. A energia reportada para o estado excitado é quase igual à do estado fundamental. No caso anterior, chegamos a ver uma energia de estado excitado que era menor do que a energia do estado fundamental reportada.
Não é possível que um cálculo variacional produza uma energia inferior à energia real do estado fundamental. No caso anterior, a energia do estado fundamental obtida não estava muito próxima do valor real. Como não obtivemos a energia real do estado fundamental naquele caso, não há contradição. No caso presente, a energia do estado fundamental estava razoavelmente próxima do valor correto, e ainda assim a energia do estado excitado parece estranhamente próxima desse mesmo valor.
Para entender melhor como isso aconteceu, lembre-se de que a forma como encontramos um estado excitado é exigindo que o estado variacional seja ortogonal ao estado fundamental (usando os circuitos de sobreposição e termos de penalidade). Se não conseguirmos obter uma energia de estado fundamental precisa (ou errarmos por alguns pontos percentuais), também não obteremos um vetor de estado fundamental preciso! Portanto, ao exigir que o estado excitado seja ortogonal ao primeiro estado encontrado, não estávamos impondo ortogonalidade com o estado fundamental real, mas sim com alguma aproximação dele (às vezes uma aproximação bastante ruim). Assim, o estado excitado não foi forçado a ser ortogonal ao estado fundamental real, e nossas estimativas de energia para os estados excitados ficaram bem próximas da energia do estado fundamental.
Essa será sempre uma preocupação no VQD. Mas, em princípio, isso pode ser corrigido aumentando o número máximo de iterações para o otimizador clássico, impondo uma tolerância menor para o otimizador clássico e, possivelmente, também tentando um ansatz diferente se estamos sistematicamente errando o estado fundamental real. Como vimos, também pode ser necessário modificar as penalidades de sobreposição (betas). Mas isso é, na verdade, uma questão separada. Nenhuma penalidade de sobreposição vai te manter longe do estado fundamental real se você ainda não encontrou uma boa estimativa do estado fundamental real para o circuito de sobreposição.
Otimização: Max-Cut
O problema do corte máximo (Max-Cut) é um problema de otimização combinatória que consiste em dividir os vértices de um grafo em dois conjuntos disjuntos de forma que o número de arestas entre os dois conjuntos seja maximizado. Mais formalmente, dado um grafo não direcionado , onde é o conjunto de vértices e é o conjunto de arestas, o problema Max-Cut pede para particionar os vértices em dois subconjuntos disjuntos, e , de modo que o número de arestas com um extremo em e o outro em seja maximizado.
Podemos aplicar o Max-Cut para resolver uma variedade de problemas, como agrupamento (clustering), design de redes e transições de fase. Vamos começar criando um grafo do problema:
import rustworkx as rx
from rustworkx.visualization import mpl_draw
n = 4
G = rx.PyGraph()
G.add_nodes_from(range(n))
# The edge syntax is (start, end, weight)
edges = [(0, 1, 1.0), (0, 2, 1.0), (0, 3, 1.0), (1, 2, 1.0), (2, 3, 1.0)]
G.add_edges_from(edges)
mpl_draw(
G, pos=rx.shell_layout(G), with_labels=True, edge_labels=str, node_color="#1192E8"
)

Esse problema pode ser expresso como um problema de otimização binária. Para cada nó , onde é o número de nós do grafo (neste caso ), vamos considerar a variável binária . Essa variável terá o valor se o nó pertencer a um dos grupos que chamaremos de , e se pertencer ao outro grupo, que chamaremos de . Também denotamos como (elemento da matriz de adjacência ) o peso da aresta que vai do nó ao nó . Como o grafo é não direcionado, . Assim, podemos formular nosso problema como a maximização da seguinte função de custo:
Para resolver esse problema com um computador quântico, vamos expressar a função de custo como o valor esperado de um observável. No entanto, os observáveis que o Qiskit admite nativamente consistem em operadores de Pauli, que têm autovalores e em vez de e . É por isso que vamos fazer a seguinte mudança de variável:
Onde . Podemos usar a matriz de adjacência para acessar comodamente os pesos de todas as arestas. Isso será utilizado para obter nossa função de custo:
Isso implica que:
Portanto, a nova função de custo que queremos maximizar é:
Além disso, a tendência natural de um computador quântico é encontrar mínimos (geralmente a menor energia) em vez de máximos, então em vez de maximizar vamos minimizar:
Agora que temos uma função de custo a minimizar cujas variáveis podem ter os valores e , podemos fazer a seguinte analogia com o Pauli :
Em outras palavras, a variável será equivalente a um gate atuando no qubit . Além disso:
Portanto, o observável que vamos considerar é:
ao qual teremos que adicionar o termo independente posteriormente:
O operador é uma combinação linear de termos com operadores Z nos nós conectados por uma aresta (lembre-se de que o qubit 0 está mais à direita): . Uma vez construído o operador, o ansatz para o algoritmo QAOA pode ser facilmente criado usando o circuito QAOAAnsatz da biblioteca de circuitos do Qiskit.
from qiskit.circuit.library import QAOAAnsatz
from qiskit.quantum_info import SparsePauliOp
max_hamiltonian = SparsePauliOp.from_list(
[("IIZZ", 1), ("IZIZ", 1), ("IZZI", 1), ("ZIIZ", 1), ("ZZII", 1)]
)
max_ansatz = QAOAAnsatz(max_hamiltonian, reps=2)
# Draw
max_ansatz.decompose(reps=3).draw("mpl")

# Sum the weights, and divide by 2
offset = -sum(edge[2] for edge in edges) / 2
print(f"""Offset: {offset}""")
Offset: -2.5
def cost_func(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
# cost = estimator.run(ansatz, hamiltonian, parameter_values=params).result().values[0]
return cost
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
estimator = Estimator()
sampler = Sampler()
Agora definimos um conjunto inicial de parâmetros aleatórios:
import numpy as np
x0 = 2 * np.pi * np.random.rand(max_ansatz.num_parameters)
print(x0)
[6.0252949 0.58448176 2.15785731 1.13646074]
Qualquer otimizador clássico pode ser usado para minimizar a função de custo. Em um sistema quântico real, um otimizador projetado para paisagens de função de custo não suaves geralmente tem melhor desempenho. Aqui usamos a rotina COBYLA do SciPy via a função minimize.
Como estamos executando iterativamente muitas chamadas ao Runtime, usamos uma sessão para executar todas as chamadas dentro de um único bloco. Além disso, para o QAOA, a solução é codificada na distribuição de saída do circuito ansatz vinculado com os parâmetros ótimos da minimização. Portanto, vamos precisar de um primitivo Sampler, e vamos instanciá-lo com a mesma sessão. E executar nossa rotina de minimização:
result = minimize(
cost_func, x0, args=(max_ansatz, max_hamiltonian, estimator), method="COBYLA"
)
print(result)
message: Optimization terminated successfully.
success: True
status: 1
fun: -2.585287311689236
x: [ 7.332e+00 3.904e-01 2.045e+00 1.028e+00]
nfev: 80
maxcv: 0.0
O vetor de solução dos ângulos de parâmetros (x), quando inserido no circuito ansatz, produz o particionamento do grafo que estávamos buscando.
eigenvalue = cost_func(result.x, max_ansatz, max_hamiltonian, estimator)
print(f"""Eigenvalue: {eigenvalue}""")
print(f"""Max-Cut Objective: {eigenvalue + offset}""")
Eigenvalue: -2.585287311689236
Max-Cut Objective: -5.085287311689235
from qiskit.result import QuasiDistribution
from qiskit.primitives import StatevectorSampler
sampler = StatevectorSampler()
# Assign solution parameters to ansatz
qc = max_ansatz.assign_parameters(result.x)
# Add measurements to our circuit
qc.measure_all()
# Sample ansatz at optimal parameters
# samp_dist = sampler.run(qc).result().quasi_dists[0]
shots = 1024
job = sampler.run([qc], shots=shots)
qc.decompose().draw("mpl")

data_pub = job.result()[0].data
bitstrings = data_pub.meas.get_bitstrings()
counts = data_pub.meas.get_counts()
quasi_dist = QuasiDistribution(
{outcome: freq / shots for outcome, freq in counts.items()}
)
probabilities = quasi_dist
# Close the session since we are now done with it
# session.close()
from qiskit.visualization import plot_distribution
plot_distribution(counts)

binary_string = max(counts.items(), key=lambda kv: kv[1])[0]
x = np.asarray([int(y) for y in reversed(list(binary_string))])
colors = ["r" if x[i] == 0 else "c" for i in range(n)]
mpl_draw(
G, pos=rx.shell_layout(G), with_labels=True, edge_labels=str, node_color=colors
)

Resumo
Com esta lição, você aprendeu:
- Como escrever um algoritmo variacional personalizado
- Como aplicar um algoritmo variacional para encontrar autovalores mínimos
- Como utilizar algoritmos variacionais para resolver casos de uso em aplicações reais