Codificação de dados
Introdução e notação
Para usar um algoritmo quântico, os dados clássicos precisam ser inseridos de alguma forma num circuito quântico. Isso costuma ser chamado de codificação de dados, mas também é denominado carregamento de dados. Relembrando as lições anteriores, temos a noção de feature mapping: um mapeamento das features dos dados de um espaço para outro. Simplesmente transferir dados clássicos para um computador quântico é uma espécie de mapeamento e poderia ser chamado de feature map. Na prática, os feature maps embutidos no Qiskit (como z_feature_map e zz_feature_map) costumam incluir camadas de rotação e camadas de entrelaçamento que estendem o estado a muitas dimensões no espaço de Hilbert. Esse processo de codificação é uma parte crítica dos algoritmos de aprendizado de máquina quântico e afeta diretamente suas capacidades computacionais.
Algumas das técnicas de codificação apresentadas abaixo podem ser simuladas de forma eficiente de modo clássico; isso é particularmente fácil de perceber em métodos de codificação que geram estados produto (ou seja, que não entrelaçam qubits). Lembre também que a vantagem quântica é mais provável de aparecer quando a complexidade quântica do conjunto de dados é bem compatível com o método de codificação. Portanto, é muito provável que você acabe escrevendo seus próprios circuitos de codificação. Aqui apresentamos uma grande variedade de estratégias de codificação possíveis simplesmente para que você possa compará-las e ver o que é viável. Existem algumas afirmações bem gerais que podem ser feitas sobre a utilidade das técnicas de codificação. Por exemplo, efficient_su2 (veja abaixo) com um esquema de entrelaçamento completo tem muito mais chance de capturar features quânticas dos dados do que métodos que geram estados produto (como z_feature_map). Mas isso não significa que efficient_su2 seja suficiente, ou suficientemente bem ajustado ao seu conjunto de dados, para produzir uma aceleração quântica. Isso requer uma análise cuidadosa da estrutura dos dados sendo modelados ou classificados. Há também um equilíbrio delicado com a profundidade do circuito, já que muitos feature maps que entrelaçam completamente os qubits num circuito produzem circuitos muito profundos — profundos demais para obter resultados utilizáveis nos computadores quânticos atuais.
Notação
Um conjunto de dados é um conjunto de vetores de dados: , onde cada vetor é -dimensional, isto é, . Isso pode ser estendido para features de dados complexas. Nesta lição, podemos ocasionalmente usar essas notações para o conjunto completo e seus elementos específicos como . Mas nos referiremos principalmente ao carregamento de um único vetor do nosso conjunto de dados por vez, e frequentemente nos referiremos simplesmente a um único vetor de features como .
Além disso, é comum usar o símbolo para se referir ao feature map do vetor de dados . Em computação quântica especificamente, é comum se referir a mapeamentos usando uma notação que reforça a natureza unitária dessas operações. Poder-se-ia usar corretamente o mesmo símbolo para ambos; ambos são feature maps. Ao longo deste curso, tendemos a usar:
- quando discutimos feature maps em aprendizado de máquina em geral, e
- quando discutimos implementações em circuitos de feature maps.
Normalização e perda de informação
No aprendizado de máquina clássico, as features dos dados de treinamento são frequentemente "normalizadas" ou reescalonadas, o que geralmente melhora o desempenho do modelo. Uma forma comum de fazer isso é usando a normalização min-max ou a padronização. Na normalização min-max, as colunas de features da matriz de dados (digamos, a feature ) são normalizadas:
onde min e max se referem ao mínimo e ao máximo da feature sobre os vetores de dados no conjunto . Todos os valores de features ficam então no intervalo unitário: para todo , .
A normalização também é um conceito fundamental em mecânica quântica e computação quântica, mas é ligeiramente diferente da normalização min-max. A normalização em mecânica quântica exige que o comprimento (no contexto de computação quântica, a 2-norma) de um vetor de estado seja igual à unidade: , garantindo que as probabilidades de medição somem 1. O estado é normalizado dividindo-se pela 2-norma; isto é, reescalonando
Em computação quântica e mecânica quântica, isso não é uma normalização imposta pelas pessoas sobre os dados, mas uma propriedade fundamental dos estados quânticos. Dependendo do seu esquema de codificação, essa restrição pode afetar como seus dados são reescalonados. Por exemplo, na codificação por amplitude (veja abaixo), o vetor de dados é normalizado conforme exigido pela mecânica quântica, e isso afeta o escalonamento dos dados sendo codificados. Na codificação por fase, recomenda-se reescalonar os valores das features como para que não haja perda de informação devido ao efeito módulo- da codificação para um ângulo de fase de qubit[1,2].
Métodos de codificação
Nas próximas seções, nos referiremos a um pequeno conjunto de dados clássico de exemplo composto por vetores de dados, cada um com features:
Na notação introduzida acima, poderíamos dizer que a feature do vetor de dados no nosso conjunto é por exemplo.
Codificação por base
A codificação por base codifica uma string clássica de bits em um estado de base computacional de um sistema de qubits. Tome por exemplo Isso pode ser representado como uma string de bits como , e por um sistema de qubits como o estado quântico . De forma mais geral, para uma string de bits: , o estado de qubits correspondente é com para . Observe que isso é apenas para uma única feature.
A codificação por base em computação quântica representa cada bit clássico como um qubit separado, mapeando a representação binária dos dados diretamente nos estados quânticos da base computacional. Quando múltiplas features precisam ser codificadas, cada feature é primeiro convertida para sua forma binária e depois atribuída a um grupo distinto de qubits — um grupo por feature — onde cada qubit reflete um bit na representação binária daquela feature.
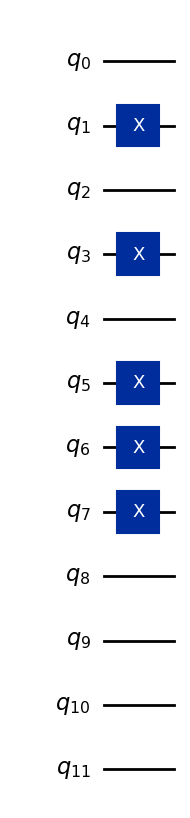
Como exemplo, vamos codificar o vetor (5, 7, 0).
Suponha que todas as features sejam armazenadas em quatro bits (mais do que precisamos, mas suficiente para representar qualquer inteiro de um único dígito na base 10):
5 → binário 0101
7 → binário 0111
0 → binário 0000
Essas strings de bits são atribuídas a três conjuntos de quatro qubits, portanto o estado de base geral de 12 qubits é:
Aqui, os primeiros quatro qubits representam a primeira feature, os próximos quatro qubits a segunda feature, e os últimos quatro qubits a terceira feature. O código abaixo converte o vetor de dados (5,7,0) em um estado quântico, e é generalizado para fazer o mesmo com outras features de um único dígito.
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit
from qiskit import QuantumCircuit
# Data point to encode
x = 5 # binary: 0101
y = 7 # binary: 0111
z = 0 # binary: 0000
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, "04b")] # [0,1,0,1]
y_bits = [int(b) for b in format(y, "04b")] # [0,1,1,1]
z_bits = [int(b) for b in format(z, "04b")] # [0,0,0,0]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,1,0,1,1,1,0,0,0,0]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw("mpl")
Verifique seu entendimento
Leia a questão abaixo, pense na sua resposta e clique no triângulo para revelar a solução.
Escreva código para codificar o primeiro vetor do nosso conjunto de dados de exemplo :
usando codificação por base.
Resposta:
import math
from qiskit import QuantumCircuit
# Data point to encode
x = 4 # binary: 0100
y = 8 # binary: 1000
z = 5 # binary: 0101
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, '04b')] # [0,1,0,0]
y_bits = [int(b) for b in format(y, '04b')] # [1,0,0,0]
z_bits = [int(b) for b in format(z, '04b')] # [0,1,0,1]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,0,1,0,0,0,0,1,0,1]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw('mpl')
Codificação por amplitude
A codificação por amplitude codifica dados nas amplitudes de um estado quântico. Ela representa um vetor de dados clássico normalizado de dimensões, , como as amplitudes de um estado quântico de qubits, :
onde é a mesma dimensão dos vetores de dados de antes, é o elemento de e é o estado de base computacional. Aqui, é uma constante de normalização a ser determinada a partir dos dados sendo codificados. Essa é a condição de normalização imposta pela mecânica quântica:
Em geral, essa é uma condição diferente da normalização min/max usada para cada feature em todos os vetores de dados. Como isso será tratado dependerá do seu problema. Mas não há como contornar a condição de normalização da mecânica quântica acima.
Na codificação por amplitude, cada feature em um vetor de dados é armazenada como a amplitude de um estado quântico diferente. Como um sistema de qubits fornece amplitudes, a codificação por amplitude de features requer qubits.
Como exemplo, vamos codificar o primeiro vetor do nosso conjunto de dados de exemplo , usando codificação por amplitude. Normalizando o vetor resultante, obtemos:
e o estado quântico de 2 qubits resultante seria:
No exemplo acima, o número de features no vetor não é uma potência de 2. Quando não é uma potência de 2, simplesmente escolhemos um valor para o número de qubits tal que e preenchemos o vetor de amplitudes com constantes não informativas (aqui, um zero).
Assim como na codificação por base, uma vez que calculamos qual estado codificará nosso conjunto de dados, no Qiskit podemos usar a função initialize para prepará-lo:
import math
desired_state = [
1 / math.sqrt(105) * 4,
1 / math.sqrt(105) * 8,
1 / math.sqrt(105) * 5,
1 / math.sqrt(105) * 0,
]
qc = QuantumCircuit(2)
qc.initialize(desired_state, [0, 1])
qc.decompose(reps=5).draw(output="mpl")

Uma vantagem da codificação por amplitude é o já mencionado requisito de apenas qubits para codificação. No entanto, algoritmos subsequentes precisam operar sobre as amplitudes de um estado quântico, e os métodos para preparar e medir os estados quânticos tendem a não ser eficientes.
Verifique seu entendimento
Leia as questões abaixo, pense nas suas respostas e clique nos triângulos para revelar as soluções.
Escreva o estado normalizado para codificar o seguinte vetor (formado por dois vetores do nosso conjunto de dados de exemplo):
usando codificação por amplitude.
Resposta:
Para codificar 6 números, precisaremos ter pelo menos 6 estados disponíveis em cujas amplitudes possamos codificar. Isso vai requerer 3 qubits. Usando um fator de normalização desconhecido , podemos escrever isso como:
Observe que
Portanto, finalmente,
Para o mesmo vetor de dados escreva código para criar um circuito que carregue essas features de dados usando codificação por amplitude.
Resposta:
desired_state = [
9 / math.sqrt(270),
8 / math.sqrt(270),
6 / math.sqrt(270),
2 / math.sqrt(270),
9 / math.sqrt(270),
2 / math.sqrt(270),
0,
0,
]
print(desired_state)
qc = QuantumCircuit(3)
qc.initialize(desired_state, [0, 1, 2])
qc.decompose(reps=8).draw(output="mpl")
[0.5477225575051662, 0.48686449556014766, 0.36514837167011077, 0.12171612389003691, 0.5477225575051662, 0.12171612389003691, 0, 0]

Pode ser necessário lidar com vetores de dados muito grandes. Considere o vetor
Escreva código para automatizar a normalização e gere um circuito quântico para codificação por amplitude.
Resposta:
Existem muitas respostas possíveis. Aqui está um código que imprime alguns passos intermediários:
import numpy as np
from math import sqrt
init_list = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5]
qubits = round(np.log(len(init_list)) / np.log(2) + 0.4999999999)
need_length = 2**qubits
pad = need_length - len(init_list)
for i in range(0, pad):
init_list.append(0)
init_array = np.array(init_list) # Unnormalized data vector
length = sqrt(
sum(init_array[i] ** 2 for i in range(0, len(init_array)))
) # Vector length
norm_array = init_array / length # Normalized array
print("Normalized array:")
print(norm_array)
print()
qubit_numbers = []
for i in range(0, qubits):
qubit_numbers.append(i)
print(qubit_numbers)
qc = QuantumCircuit(qubits)
qc.initialize(norm_array, qubit_numbers)
qc.decompose(reps=7).draw(output="mpl")
Normalized array: [0.17342199 0.34684399 0.21677749 0.39019949 0.34684399 0.26013299 0.086711 0.39019949 0.086711 0.21677749 0.30348849 0. 0.1300665 0.30348849 0.21677749 0. ]
[0, 1, 2, 3]
Você consegue ver vantagens da codificação por amplitude em relação à codificação por base? Se sim, explique.
Resposta:
Pode haver várias respostas. Uma delas é que, dada a ordenação fixa dos estados de base, essa codificação por amplitude preserva a ordem dos números codificados. Frequentemente também será codificada de forma mais densa.
Um benefício da codificação por amplitude é que apenas qubits são necessários para um vetor de dados -dimensional ( features) . No entanto, a codificação por amplitude é geralmente um procedimento ineficiente que requer preparação de estado arbitrária, que é exponencial no número de portas CNOT. Dito de outra forma, a preparação do estado tem uma complexidade de tempo polinomial de no número de dimensões, onde , e é o número de qubits. A codificação por amplitude "proporciona uma economia exponencial em espaço ao custo de um aumento exponencial em tempo"[3]; no entanto, aumentos de tempo de execução para são alcançáveis em certos casos[4]. Para uma aceleração quântica de ponta a ponta, a complexidade de tempo de carregamento dos dados precisa ser considerada.
Codificação por ângulo
A codificação por ângulo é de interesse em muitos modelos de QML que usam feature maps de Pauli, como máquinas de suporte vetorial quânticas (QSVMs) e circuitos quânticos variacionais (VQCs), entre outros. A codificação por ângulo está intimamente relacionada à codificação por fase e à codificação por ângulo densa, apresentadas abaixo. Aqui usaremos "codificação por ângulo" para nos referir a uma rotação em , ou seja, uma rotação para longe do eixo realizada, por exemplo, por uma porta ou uma porta [1,3]. Na prática, pode-se codificar dados em qualquer rotação ou combinação de rotações. Mas é comum na literatura, então enfatizamos isso aqui.
Quando aplicada a um único qubit, a codificação por ângulo impõe uma rotação em torno do eixo Y proporcional ao valor do dado. Considere a codificação de uma única feature () do vetor de dados de um conjunto, :
Alternativamente, a codificação por ângulo pode ser realizada usando portas , embora o estado codificado tenha uma fase relativa complexa em comparação com .
A codificação por ângulo é diferente dos dois métodos anteriores discutidos em vários aspectos. Na codificação por ângulo:
- Cada valor de feature é mapeado para um qubit correspondente, , deixando os qubits em um estado produto.
- Um valor numérico é codificado por vez, em vez de um conjunto inteiro de features de um ponto de dado.
- qubits são necessários para features de dados, onde . Com frequência, a igualdade se aplica aqui. Veremos como é possível nas próximas seções.
- O circuito resultante tem profundidade constante (tipicamente a profundidade é 1 antes da transpilação).
O circuito quântico de profundidade constante o torna particularmente adequado para o hardware quântico atual. Uma característica adicional de codificar nossos dados usando (e especificamente, nossa escolha de usar a codificação por ângulo no eixo Y) é que ela cria estados quânticos de valor real que podem ser úteis para certas aplicações. Para a rotação no eixo Y, os dados são mapeados com uma porta de rotação no eixo Y por um ângulo de valor real (Qiskit RYGate). Assim como na codificação por fase (veja abaixo), recomendamos que você reescalone os dados de forma que , prevenindo perda de informação e outros efeitos indesejados.
O código Qiskit a seguir rotaciona um único qubit de um estado inicial para codificar um valor de dado .
from qiskit.quantum_info import Statevector
from math import pi
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
Vamos definir uma função para visualizar a ação sobre o vetor de estado. Os detalhes da definição da função não são importantes, mas a capacidade de visualizar os vetores de estado e suas mudanças é importante.
import numpy as np
from qiskit.visualization.bloch import Bloch
from qiskit.visualization.state_visualization import _bloch_multivector_data
def plot_Nstates(states, axis, plot_trace_points=True):
"""This function plots N states to 1 Bloch sphere"""
bloch_vecs = [_bloch_multivector_data(s)[0] for s in states]
if axis is None:
bloch_plot = Bloch()
else:
bloch_plot = Bloch(axes=axis)
bloch_plot.add_vectors(bloch_vecs)
if len(states) > 1:
def rgba_map(x, num):
g = (0.95 - 0.05) / (num - 1)
i = 0.95 - g * num
y = g * x + i
return (0.0, y, 0.0, 0.7)
num = len(states)
bloch_plot.vector_color = [rgba_map(x, num) for x in range(1, num + 1)]
bloch_plot.vector_width = 3
bloch_plot.vector_style = "simple"
if plot_trace_points:
def trace_points(bloch_vec1, bloch_vec2):
# bloch_vec = (x,y,z)
n_points = 15
thetas = np.arccos([bloch_vec1[2], bloch_vec2[2]])
phis = np.arctan2(
[bloch_vec1[1], bloch_vec2[1]], [bloch_vec1[0], bloch_vec2[0]]
)
if phis[1] < 0:
phis[1] = phis[1] + 2 * pi
angles0 = np.linspace(phis[0], phis[1], n_points)
angles1 = np.linspace(thetas[0], thetas[1], n_points)
xp = np.cos(angles0) * np.sin(angles1)
yp = np.sin(angles0) * np.sin(angles1)
zp = np.cos(angles1)
pnts = [xp, yp, zp]
bloch_plot.add_points(pnts)
bloch_plot.point_color = "k"
bloch_plot.point_size = [4] * len(bloch_plot.points)
bloch_plot.point_marker = ["o"]
for i in range(len(bloch_vecs) - 1):
trace_points(bloch_vecs[i], bloch_vecs[i + 1])
bloch_plot.sphere_alpha = 0.05
bloch_plot.frame_alpha = 0.15
bloch_plot.figsize = [4, 4]
bloch_plot.render()
plot_Nstates(states, axis=None, plot_trace_points=True)

Isso foi apenas uma única feature de um único vetor de dados. Ao codificar features nos ângulos de rotação de qubits, digamos para o vetor de dados o estado produto codificado ficará assim:
Observamos que isso é equivalente a
Verifique seu entendimento
Leia as questões abaixo, pense nas suas respostas e clique nos triângulos para revelar as soluções.
Codifique o vetor de dados usando codificação por ângulo, como descrito acima.
Resposta:
qc = QuantumCircuit(3)
qc.ry(0, 0)
qc.ry(2 * math.pi / 4, 1)
qc.ry(2 * math.pi / 2, 2)
qc.draw(output="mpl")

Usando a codificação por ângulo como descrita acima, quantos qubits são necessários para codificar 5 features?
Resposta: 5
Codificação por fase
A codificação por fase é muito semelhante à codificação por ângulo descrita acima. O ângulo de fase de um qubit é um ângulo de valor real em torno do eixo a partir do eixo . Os dados são mapeados com uma rotação de fase, , onde (veja Qiskit PhaseGate para mais informações). Recomenda-se reescalonar os dados de forma que . Isso previne a perda de informação e outros efeitos potencialmente indesejados[1,2].
Um qubit geralmente é inicializado no estado , que é um autoestado do operador de rotação de fase, o que significa que o estado do qubit precisa primeiro ser rotacionado para que a codificação por fase seja implementada. Portanto, faz sentido inicializar o estado com uma porta Hadamard: . A codificação por fase em um único qubit significa imprimir uma fase relativa proporcional ao valor do dado:
O procedimento de codificação por fase mapeia cada valor de feature para a fase de um qubit correspondente, . No total, a codificação por fase tem uma profundidade de circuito de 2, incluindo a camada Hadamard, o que a torna um esquema de codificação eficiente. O estado de múltiplos qubits codificado por fase ( qubits para features) é um estado produto:
O código Qiskit a seguir primeiro prepara o estado inicial de um único qubit rotacionando-o com uma porta Hadamard, e depois o rotaciona novamente usando uma porta de fase para codificar uma feature de dado .
qc = QuantumCircuit(1)
qc.h(0) # Hadamard gate rotates state down to Bloch equator
state1 = Statevector.from_instruction(qc)
qc.p(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
qc.draw("mpl", scale=1)

Podemos visualizar a rotação em usando a função plot_Nstates que definimos.
plot_Nstates(states, axis=None, plot_trace_points=True)

O gráfico da esfera de Bloch mostra a rotação no eixo Z onde . A seta verde claro mostra o estado final.
A codificação por fase é usada em muitos feature maps quânticos, particularmente nos feature maps e , e em feature maps de Pauli em geral, entre outros.
Verifique seu entendimento
Leia as questões abaixo, pense nas suas respostas e clique nos triângulos para revelar as soluções.
Quantos qubits são necessários para usar a codificação por fase como descrita acima para armazenar 8 features?
Resposta: 8
Escreva código para o vetor usando codificação por fase.
Resposta:
Pode haver muitas respostas. Aqui está um exemplo:
phase_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0]
qc = QuantumCircuit(len(phase_data))
for i in range(0, len(phase_data)):
qc.h(i)
qc.rz(phase_data[i] * 2 * math.pi / float(max(phase_data)), i)
qc.draw(output="mpl")

Codificação por ângulo densa
A codificação por ângulo densa (DAE, do inglês dense angle encoding) é uma combinação de codificação por ângulo e codificação por fase. A DAE permite que dois valores de features sejam codificados em um único qubit: um ângulo com uma rotação no eixo Y, e o outro com uma rotação no eixo : . Ela codifica duas features da seguinte forma:
Codificar dois dados em um qubit resulta numa redução de no número de qubits necessários para a codificação. Estendendo isso para mais features, o vetor de dados pode ser codificado como:
A DAE pode ser generalizada para funções arbitrárias das duas features em vez das funções senoidais usadas aqui. Isso é chamado de codificação geral de qubit (general qubit encoding)[7].
Como exemplo de DAE, o código abaixo codifica e visualiza a codificação das features e .
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(3 * pi / 8, 0)
state2 = Statevector.from_instruction(qc)
qc.rz(7 * pi / 4, 0)
state3 = Statevector.from_instruction(qc)
states = state1, state2, state3
plot_Nstates(states, axis=None, plot_trace_points=True)

Verifique seu entendimento
Leia as questões abaixo, pense nas suas respostas e clique nos triângulos para revelar as soluções.
Dado o tratamento acima, quantos qubits são necessários para codificar 6 features usando a codificação densa?
Resposta: 3
Escreva código para carregar o vetor usando codificação por ângulo densa.
Resposta:
Observe que preenchemos a lista com um "0" para evitar o problema de haver um único parâmetro não utilizado no nosso esquema de codificação.
dense_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5, 0]
qc = QuantumCircuit(int(len(dense_data) / 2))
entry = 0
for i in range(0, int(len(dense_data) / 2)):
qc.ry(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.rz(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.draw(output="mpl")

Codificação com feature maps integrados
Codificando em pontos arbitrários
A codificação por ângulo, codificação por fase e codificação densa preparavam estados produto com uma feature codificada em cada qubit (ou duas features por qubit). Isso é diferente da codificação por base e da codificação por amplitude, pois esses métodos fazem uso de estados entrelaçados. Não há uma correspondência 1:1 entre a feature do dado e o qubit. Na codificação por amplitude, por exemplo, uma feature pode ser a amplitude do estado e outra feature pode ser a amplitude do estado . Em geral, métodos que codificam em estados produto produzem circuitos mais rasos e podem armazenar 1 ou 2 features em cada qubit. Métodos que usam entrelaçamento e associam uma feature a um estado em vez de a um qubit resultam em circuitos mais profundos e podem armazenar mais features por qubit em média.
Mas a codificação não precisa ser inteiramente em estados produto ou inteiramente em estados entrelaçados como na codificação por amplitude. Na verdade, muitos esquemas de codificação integrados ao Qiskit permitem codificar tanto antes quanto depois de uma camada de entrelaçamento, em vez de apenas no início. Isso é conhecido como "data reuploading". Para trabalhos relacionados, veja as referências [5] e [6].
Nesta seção, vamos usar e visualizar alguns dos esquemas de codificação integrados. Todos os métodos desta seção codificam features como rotações em portas parametrizadas em qubits, onde . Note que maximizar o carregamento de dados para um determinado número de qubits não é a única consideração. Em muitos casos, a profundidade do circuito pode ser uma consideração ainda mais importante do que a contagem de qubits.
Efficient SU2
Um exemplo comum e útil de codificação com entrelaçamento é o circuito efficient_su2 do Qiskit. De forma impressionante, esse circuito pode, por exemplo, codificar 8 features em apenas 2 qubits. Vamos ver isso e depois tentar entender como é possível.
from qiskit.circuit.library import efficient_su2
circuit = efficient_su2(num_qubits=2, reps=1, insert_barriers=True)
circuit.decompose().draw(output="mpl")

Ao escrever nosso estado, usaremos a convenção do Qiskit de que os qubits menos significativos são ordenados à direita, como em ou Esses estados podem se tornar muito complicados muito rapidamente, e esse raro exemplo pode ajudar a explicar por que tais estados raramente são escritos explicitamente.
Nosso sistema começa no estado Até a primeira barreira (um ponto que rotulamos ), nossos estados são:
Isso é apenas codificação densa, que já vimos antes. Agora, após a porta CNOT, na segunda barreira (), nosso estado é
Agora aplicamos o último conjunto de rotações de qubit único e agrupamos os estados semelhantes para obter:
Isso provavelmente é complicado demais para interpretar. Em vez disso, dê um passo atrás e pense em quantos parâmetros carregamos no estado: oito. Mas temos apenas quatro estados da base computacional. À primeira vista, pode parecer que carregamos mais parâmetros do que faz sentido, já que o estado final pode ser escrito como . Note, porém, que cada prefator é complexo! Escrito assim:
Pode-se ver que temos, de fato, oito parâmetros no estado nos quais codificar nossas oito features.
Ao aumentar o número de qubits e o número de repetições das camadas de entrelaçamento e rotação, é possível codificar muito mais dados. Escrever as funções de onda rapidamente se torna inviável. Mas ainda podemos ver a codificação em ação.
Aqui codificamos o vetor de dados com 12 features, em um circuito efficient_su2 de 3 qubits, usando cada uma das portas parametrizadas para codificar uma feature diferente.
Neste vetor de dados, as features são mostradas em uma ordem específica. De forma isolada, não importa se elas são codificadas nessa ordem ou na ordem inversa. O que é importante é manter o controle disso e ser consistente. Note no diagrama do circuito que efficient_su2 assume uma certa ordem de codificação, especificamente preenchendo a primeira camada de portas parametrizadas do qubit 0 ao qubit 2, e depois passando para a próxima camada. Isso não é nem consistente nem inconsistente com a notação little-endian, pois aqui as features dos dados não podem ser ordenadas por qubit a priori, antes que um circuito de codificação tenha sido especificado.
x = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2]
circuit = efficient_su2(num_qubits=3, reps=1, insert_barriers=True)
encode = circuit.assign_parameters(x)
encode.decompose().draw(output="mpl")

Em vez de aumentar o número de qubits, você pode optar por aumentar o número de repetições das camadas de entrelaçamento e rotação. Mas há limites para quantas repetições são úteis. Como dito anteriormente, há uma troca: circuitos com mais qubits ou mais repetições de camadas de entrelaçamento e rotação podem armazenar mais parâmetros, mas o fazem com maior profundidade de circuito. Voltaremos às profundidades de alguns feature maps integrados mais adiante. Os próximos métodos de codificação integrados ao Qiskit têm "feature map" como parte de seus nomes. Vale reiterar que codificar dados em um circuito quântico é um mapeamento de features, no sentido de que leva os dados a um novo espaço: o espaço de Hilbert dos qubits envolvidos. A relação entre a dimensionalidade do espaço de features original e o do espaço de Hilbert dependerá do circuito que você usar para a codificação.
Feature map
O feature map (ZFM) pode ser interpretado como uma extensão natural da codificação por fase. O ZFM consiste em camadas alternadas de portas de qubit único: camadas de porta Hadamard e camadas de porta de fase. Seja o vetor de dados com features. O circuito quântico que realiza o mapeamento de features é representado como um operador unitário que age sobre o estado inicial:
onde é o estado fundamental de qubits. Essa notação é usada para consistência com a referência [4] de Havlicek et al. As features de dados são mapeadas um-a-um com os qubits correspondentes. Por exemplo, se você tem 8 features em um vetor de dados, usaria 8 qubits. O circuito ZFM é composto por repetições de um subcircuito formado por camadas de porta Hadamard e camadas de porta de fase. Uma camada Hadamard é formada por uma porta Hadamard agindo em cada qubit de um registrador de qubits, , no mesmo estágio do algoritmo. Essa descrição também se aplica a uma camada de porta de fase em que o qubit é acionado por . Cada porta tem uma feature como argumento, mas a camada de porta de fase ( é uma função do vetor de dados. O unitário completo do circuito ZFM com uma única repetição é:
Então repetições desse unitário seriam
As features de dados, , são mapeadas para as portas de fase da mesma forma em todas as repetições. O estado do feature map ZFM é um estado produto e é eficiente para simulação clássica[4].
Para começar com um exemplo pequeno, um circuito ZFM de dois qubits é codificado usando o Qiskit e desenhado para exibir a estrutura simples do circuito. No exemplo, uma única repetição, , é implementada com o vetor de dados . Note que isso é escrito na ordem padrão de um vetor em Python, o que significa que o elemento de índice é Podemos codificar essa feature de índice no nosso qubit , ou no qubit Novamente, nem sempre pode haver um mapeamento único 1:1 da ordem das features para a ordem dos qubits, pois diferentes feature maps codificam diferentes números de features em cada qubit. O que importa, novamente, é que estejamos cientes de onde cada feature está sendo codificada. Ao fornecer uma lista de parâmetros para o feature map , ele codificará a feature 0 da lista no qubit menos significativo com uma porta parametrizada, como no qubit 0. Então seguiremos essa convenção ao fazer isso manualmente. Codificaremos no qubit e no qubit .
O operador unitário do circuito ZFM age sobre o estado inicial da seguinte forma:
A fórmula foi reorganizada em torno do produto tensorial para enfatizar as operações em cada qubit. O código Qiskit a seguir usa portas Hadamard e de fase explicitamente para mostrar a estrutura do ZFM:
qc0 = QuantumCircuit(1)
qc1 = QuantumCircuit(1)
qc0.h(0)
qc0.p(pi / 2, 0)
qc1.h(0)
qc1.p(pi / 3, 0)
# Combine circuits qc0 and qc1 into 1 circuit
qc = QuantumCircuit(2)
qc.compose(qc0, [0], inplace=True)
qc.compose(qc1, [1], inplace=True)
qc.draw("mpl", scale=1)

Agora codificamos o mesmo vetor de dados em um circuito ZFM com três repetições, , usando a classe z_feature_map do Qiskit, o que no total nos dá o feature map quântico . Por padrão na classe z_feature_map, os parâmetros são multiplicados por 2 antes de serem mapeados para a porta de fase . Para reproduzir as mesmas codificações acima, dividimos por 2.
from qiskit.circuit.library import z_feature_map
zfeature_map = z_feature_map(feature_dimension=2, reps=3)
zfeature_map = zfeature_map.assign_parameters([(1 / 2) * pi / 2, (1 / 2) * pi / 3])
zfeature_map.decompose().draw("mpl")

Claramente, esse é um mapeamento diferente do feito manualmente acima, mas note a consistência na ordenação dos parâmetros: foi novamente codificado no qubit .
Você pode usar o ZFM por meio da classe ZFM do Qiskit; também pode usar essa estrutura como inspiração para construir seu próprio mapeamento de features.
Feature map
O feature map (ZZFM) estende o ZFM com a inclusão de portas de entrelaçamento de dois qubits, especificamente a porta de rotação , . Conjectura-se que o ZZFM seja geralmente caro para computar em um computador clássico, ao contrário do ZFM.
implementa uma interação e é maximalmente entrelaçante para . pode ser decomposto em uma série de portas em dois qubits, como mostrado no código Qiskit a seguir usando a porta RZZ e o método decompose da classe QuantumCircuit. Codificamos uma única feature do vetor de dados :
qc = QuantumCircuit(2)
qc.rzz(pi, 0, 1)
qc.draw("mpl", scale=1)

Como costuma ser o caso, vemos isso representado como uma única unidade semelhante a uma porta, até usarmos .decompose() para ver todas as portas constituintes.
qc.decompose().draw("mpl", scale=1)

Os dados são mapeados com uma rotação de fase no segundo qubit. A porta entrelaça os dois qubits nos quais opera por um grau de entrelaçamento determinado pelo valor da feature codificada.
O circuito ZZFM completo consiste em uma porta Hadamard e uma porta de fase, como no ZFM, seguidas do entrelaçamento descrito acima. Uma única repetição do circuito ZZFM é:
onde contém uma camada de portas ZZ estruturada por um esquema de entrelaçamento. Vários esquemas de entrelaçamento são mostrados nos blocos de código abaixo. A estrutura de também inclui uma função que combina as features de dados dos qubits sendo entrelaçados da seguinte forma. Digamos que a porta será aplicada aos qubits e . Na camada de fase, esses qubits têm portas de fase que codificam e neles, respectivamente. O argumento do não será simplesmente uma dessas features ou a outra, mas uma função frequentemente denotada por (não confundir com o ângulo azimutal):
Veremos isso em vários exemplos abaixo. A extensão para múltiplas repetições é a mesma que no caso do z_feature_map:
Como os operadores aumentaram em complexidade, vamos primeiro codificar um vetor de dados com um ZZFM de dois qubits e uma repetição usando o código a seguir:
from qiskit.circuit.library import zz_feature_map
feature_dim = 2
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose(reps=1).draw("mpl", scale=1)

Por padrão no Qiskit, as features são mapeadas juntas para por essa função de mapeamento . O Qiskit permite ao usuário personalizar a função (ou onde é o conjunto de pares de qubits acoplados por portas ) como etapa de pré-processamento.
Passando para um vetor de dados de quatro dimensões e mapeando para um ZZFM de quatro qubits com uma repetição, podemos começar a ver o mapeamento para vários pares de qubits. Também podemos ver o significado de entrelaçamento "linear":
feature_dim = 4
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose().draw("mpl", scale=1)

No esquema de entrelaçamento linear, pares vizinhos (numerados) de qubits neste circuito são entrelaçados. Há outros esquemas de entrelaçamento integrados no Qiskit, incluindo circular e full.
Feature map de Pauli
O feature map de Pauli (PFM) é a generalização do ZFM e do ZZFM para usar portas de Pauli arbitrárias. O feature map de Pauli tem uma forma muito semelhante aos dois feature maps anteriores. Para repetições da codificação das features do vetor
Para o PFM, é generalizado para um operador unitário de expansão de Pauli. Aqui apresentamos uma forma mais generalizada dos feature maps considerados até agora:
onde é um operador de Pauli, . Aqui é o conjunto de todas as conectividades de qubits conforme determinado pelo feature map, incluindo o conjunto de qubits acionados por portas de qubit único. Ou seja, para um feature map no qual o qubit 0 é acionado por uma porta de fase, e os qubits 2 e 3 são acionados por uma porta , o conjunto incluiria . percorre todos os elementos desse conjunto. Nos feature maps anteriores, a função estava envolvida exclusivamente com portas de qubit único ou exclusivamente com portas de dois qubits. Aqui, a definimos de forma geral:
Para a documentação, veja a documentação da classe Pauli feature map do Qiskit). No ZZFM, o operador é restrito a .
Uma forma de entender o unitário acima é por analogia com o propagador em um sistema físico. O unitário acima é um operador de evolução unitária, , para um Hamiltoniano , similar ao modelo de Ising, onde o parâmetro de tempo é substituído por valores de dados para conduzir a evolução. A expansão desse operador unitário fornece o circuito PFM. As conectividades de entrelaçamento em podem ser interpretadas como acoplamentos de Ising em uma rede de spins.
Vamos considerar um exemplo de operadores de Pauli e representando essas interações do tipo Ising. O Qiskit fornece uma classe pauli_feature_map para instanciar um PFM com uma escolha de portas de qubit único e qubits, que neste exemplo serão passadas como strings de Pauli 'Y' e 'XX'. Tipicamente, é 1 ou 2 para interações de um e dois qubits, respectivamente. O esquema de entrelaçamento é "linear", o que significa que apenas qubits vizinhos no circuito quântico são acoplados. Note que isso não corresponde a qubits vizinhos no computador quântico em si, pois este circuito quântico é uma camada de abstração.
from qiskit.circuit.library import pauli_feature_map
feature_dim = 3
pfmap = pauli_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1, paulis=["Y", "XX"]
)
pfmap.decompose().draw("mpl", scale=1.5)

O Qiskit fornece um parâmetro nos feature maps de Pauli para controlar o escalonamento das rotações de Pauli.
O valor padrão de é . Ao otimizar seu valor no intervalo, por exemplo, pode-se alinhar melhor um kernel quântico aos dados.
Galeria de feature maps de Pauli
Aqui visualizamos vários feature maps de Pauli para circuitos de dois qubits, para ter uma ideia melhor da gama de possibilidades.
from qiskit.visualization import circuit_drawer
import matplotlib.pyplot as plt
feature_dim = 2
fig, axs = plt.subplots(9, 2)
i_plot = 0
for paulis in [
["I"],
["X"],
["Y"],
["Z"],
["XX"],
["XY"],
["XZ"],
["YY"],
["YZ"],
["ZZ"],
["X", "ZZ"],
["Y", "ZZ"],
["Z", "ZZ"],
["X", "YZ"],
["Y", "YZ"],
["Z", "YZ"],
["YY", "ZZ"],
["XY", "ZZ"],
]:
pfmap = pauli_feature_map(feature_dimension=feature_dim, paulis=paulis, reps=1)
circuit_drawer(
pfmap.decompose(),
output="mpl",
style={"backgroundcolor": "#EEEEEE"},
ax=axs[int((i_plot - i_plot % 2) / 2), i_plot % 2],
)
axs[int((i_plot - i_plot % 2) / 2), i_plot % 2].title.set_text(paulis)
i_plot += 1
fig.set_figheight(16)
fig.set_figwidth(16)
O acima pode, é claro, ser estendido para incluir outras permutações e repetições de matrizes de Pauli. Encorajamos os estudantes a experimentar com essas opções.
Revisão dos feature maps integrados
Você viu vários esquemas para codificar dados em um circuito quântico:
- Codificação por base
- Codificação por amplitude
- Codificação por ângulo
- Codificação por fase
- Codificação densa
Você viu como construir seus próprios feature maps usando esses esquemas de codificação, e viu quatro feature maps integrados que aproveitam a codificação por ângulo e por fase:
- Efficient SU2
- Feature map Z
- Feature map ZZ
- Feature map de Pauli
Esses feature maps integrados se diferenciaram uns dos outros de várias formas:
- A profundidade para um dado número de features codificadas
- O número de qubits necessários para um dado número de features
- O grau de entrelaçamento (obviamente relacionado às outras diferenças)
O código abaixo aplica esses quatro feature maps integrados à codificação de um conjunto de features e plota a profundidade de dois qubits do circuito resultante. Como as taxas de erro de dois qubits são muito mais altas do que as de portas de qubit único, pode-se razoavelmente ter maior interesse na profundidade das portas de dois qubits. No código abaixo, obtemos contagens de todas as portas em um circuito primeiro decompondo o circuito e depois usando count_ops(), como mostrado abaixo. Aqui as portas de dois qubits que nos interessam são as portas 'cx':
# Initializing parameters and empty lists for depths
x = [0.1, 0.2]
n_data = []
zz2gates = []
su22gates = []
z2gates = []
p2gates = []
# Generating feature maps
for n in range(3, 10):
x.append(n / 10)
zzcircuit = zz_feature_map(n, reps=1, insert_barriers=True)
zcircuit = z_feature_map(n, reps=1, insert_barriers=True)
su2circuit = efficient_su2(n, reps=1, insert_barriers=True)
pcircuit = pauli_feature_map(n, reps=1, paulis=["XX"], insert_barriers=True)
# Getting the cx depths
zzcx = zzcircuit.decompose().count_ops().get("cx")
zcx = zcircuit.decompose().count_ops().get("cx")
su2cx = su2circuit.decompose().count_ops().get("cx")
pcx = pcircuit.decompose().count_ops().get("cx")
# Appending the cx gate counts to the lists. We shift the zz and Pauli data points,
# because they overlap.
n_data.append(n)
zz2gates.append(zzcx - 0.5)
z2gates.append(0)
su22gates.append(su2cx)
p2gates.append(pcx + 0.5)
# Plot the output
plt.plot(n_data, p2gates, "bo")
plt.plot(n_data, zz2gates, "ro")
plt.plot(n_data, su22gates, "yo")
plt.plot(n_data, z2gates, "go")
plt.ylabel("CX Gates")
plt.xlabel("Data elements")
plt.legend(["Pauli", "ZZ", "SU2", "Z"])
# plt.suptitle('zz_feature_map(n)')
plt.show()
Em geral, os feature maps Pauli e ZZ resultarão em maior profundidade de circuito e maior número de portas de 2 qubits do que o efficient_su2 e o feature map Z.
Como os feature maps integrados ao Qiskit são amplamente aplicáveis, muitas vezes não precisaremos projetar os nossos próprios, especialmente na fase de aprendizado. No entanto, especialistas em aprendizado de máquina quântico provavelmente voltarão ao tema de projetar seu próprio mapeamento de features, ao enfrentarem dois desafios complexos:
-
Hardware moderno: a presença de ruído e o grande overhead de código de correção de erros significa que as aplicações atuais precisarão considerar coisas como eficiência de hardware e minimização da profundidade de portas de dois qubits.
-
Mapeamentos que se adequam ao problema em questão: Uma coisa é dizer que o
zz_feature_map, por exemplo, é difícil de simular classicamente, e portanto interessante. Outra coisa bem diferente é ozz_feature_mapser ideal para sua tarefa de aprendizado de máquina ou conjunto de dados. O desempenho de diferentes circuitos quânticos parametrizados em diferentes tipos de dados é uma área ativa de investigação.
Encerramos com uma observação sobre eficiência de hardware.
Mapeamento de features eficiente em hardware
Um mapeamento de features eficiente em hardware é aquele que leva em conta as restrições de computadores quânticos reais, com o objetivo de reduzir ruído e erros na computação. Ao rodar circuitos quânticos em computadores quânticos de curto prazo, há muitas estratégias para mitigar o ruído inerente ao hardware. Uma estratégia principal para eficiência de hardware é a minimização da profundidade do circuito quântico, para que o ruído e a decoerência tenham menos tempo para corromper a computação. A profundidade de um circuito quântico é o número de etapas de portas alinhadas temporalmente necessárias para completar toda a computação (após a otimização do circuito)[5]. Lembre-se de que a profundidade do circuito lógico abstrato pode ser muito menor do que a profundidade após o circuito ser transpilado para um computador quântico real.
A transpilação é o processo de converter o circuito quântico de uma abstração de alto nível para um que esteja pronto para rodar em um computador quântico real, levando em conta as restrições do hardware. Um computador quântico tem um conjunto nativo de portas de qubit único e de dois qubits. Isso significa que todas as portas no código Qiskit precisam ser transpiladas para o conjunto de portas de hardware nativas. Por exemplo, no ibm_torino, um QPU com um processador Heron r1 concluído em 2023, as portas nativas ou de base são {CZ, ID, RZ, SX, X}. São elas a porta de dois qubits controlled-Z, e portas de qubit único chamadas identidade, rotação-, raiz quadrada de NOT, e NOT, respectivamente, fornecendo um conjunto universal. Ao implementar portas de múltiplos qubits como um subcircuito equivalente, são necessárias portas físicas de dois qubits , juntamente com outras portas de qubit único disponíveis no hardware. Além disso, para realizar uma porta de dois qubits em um par de qubits que não estão fisicamente acoplados, portas SWAP são adicionadas para mover os estados de qubits entre qubits para permitir o acoplamento, o que leva a uma extensão inevitável do circuito. Usando o argumento optimization que pode ser definido de 0 até um nível máximo de 3. Para maior controle e personalização, o pipeline do transpilador pode ser gerenciado com o Qiskit Pass Manager. Consulte a documentação do Transpilador Qiskit para mais informações sobre transpilação.
Em Havlicek et al. 2019 [2], uma forma como os autores alcançam eficiência de hardware é usando o feature map porque ele é uma expansão de segunda ordem (veja a seção "feature map " acima). Uma expansão de ordem tem portas de qubits. Os computadores quânticos IBM® não possuem portas nativas de qubits, onde , portanto implementá-las exigiria decomposição em portas CNOT de dois qubits disponíveis no hardware. Uma segunda forma pela qual os autores minimizam a profundidade é escolhendo uma topologia de acoplamento que mapeia diretamente para os acoplamentos da arquitetura. Uma otimização adicional que eles realizam é selecionar um subcircuito de hardware de alto desempenho e adequadamente conectado. Outras coisas a considerar são minimizar o número de repetições do feature map e escolher um esquema de entrelaçamento personalizado de baixa profundidade ou "linear" em vez do esquema "full" que entrelaça todos os qubits.

O gráfico acima mostra uma rede de nós e arestas que representam qubits físicos e acoplamentos de hardware, respectivamente. O mapa de acoplamento e o desempenho do ibm_torino são mostrados com todas as possíveis portas de acoplamento CZ de dois qubits. Os qubits são codificados por cores em uma escala baseada no tempo de relaxação T1 em microssegundos (μs), onde tempos T1 mais longos são melhores e em um tom mais claro. As arestas de acoplamento são codificadas por cores pelo erro CZ, onde tons mais escuros são melhores. Informações sobre a especificação do hardware podem ser acessadas no esquema de configuração do backend de hardware IBMQBackend.configuration().
Referências
- Maria Schuld and Francesco Petruccione, Supervised Learning with Quantum Computers, Springer 2018, doi:10.1007/978-3-319-96424-9.
- Vojtech Havlicek et al., "Supervised Learning with Quantum Enhanced Feature Spaces." Nature, vol. 567 (2019): 209–212. https://arxiv.org/abs/1804.11326.
- Ryan LaRose and Brian Coyle, "Robust data encodings for quantum classifiers", Physical Review A 102, 032420 (2020), doi:10.1103/PhysRevA.102.032420, arXiv:2003.01695.
- Lou Grover and Terry Rudolph. "Creating Superpositions That Correspond to Efficiently Integrable Probability Distributions." arXiv:quant-ph/0208112, August 15, 2002, https://arxiv.org/abs/quant-ph/0208112.
- Adrián Pérez-Salinas, Alba Cervera-Lierta, Elies Gil-Fuster, José I. Latorre, "Data re-uploading for a universal quantum classifier", Quantum 4, 226 (2020), ArXiv.org/abs/1907.02085.
- Maria Schuld, Ryan Sweke, Johannes Jakob Meyer, "The effect of data encoding on the expressive power of variational quantum machine learning models", Phys. Rev. A 103, 032430 (2021), arxiv.org/abs/2008.08605
import qiskit
qiskit.version.get_version_info()